『退屈なことはPythonにやらせよう』その9(11章:Webスクレイピング)
Python初心者です。『退屈なことはPythonにやらせよう』を走っています。
9回目の今回は、11章をやっていきます~。
前回の記事はこちら↓
本章では、以下のことについて学びました。
- webbrowserモジュールは単純にURLを開くだけ
- requestsモジュールならWebページのダウンロードもできる
- HTMLの分析には正規表現は使わない(+開発者ツールの使い方)
- BeautifulSoupモジュールでHTMLを解析(本文中のコード例は”html.parsar”が欠如しているし、なぜか”.r”がうまく探せなかった)
- Seleniumモジュールを用いてブラウザを制御する
ここの新しい知識をふんだんに活用して、4つの課題に取り組んでいきます。
また、Unicodeエンコーディングとはなんぞや?みたいな疑問に答えてくれるサイトが紹介されています。(どちらも英語です)
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
- Pragmatic Unicode
また、1については日本語訳を載せてくれている方がいました。
「ソフトウェア開発者なら絶対知っておくべき!Unicodeと文字セットについての最低限の知識」
村上春樹さんの小説に出てくる人物みたいな語り口でけっこう好きな文章でした(そこじゃない)。
requests.getを用いて取得したHTMLなどのWebサイトをopen()とwrite()で保存します。
その時にopen()のモードを “wb” として、バイナリで書き込む必要があるのですが、その理由を理解するための記事みたいです。
今回の目次
PythonでCeleniumモジュールを使ったコマンドライン電子メーラー
課題のクリア条件
コマンドラインから引数として
- メールアドレス
- 本文テキスト
- メールの題名(勝手に追加)
を受け取り、メールサービスにログインしてメールを送る。
とりあえずそれ用にYahoo mailのアカウントを作りました。
Celeniumについて、ページの要素を見つけるメソッドとして本書で紹介されていたのは
- browser.find_element(s)_by_class_name(name)
- browser.find_element(s)_by_css_selector(selector)
- browser.find_element(s)_by_id(id)
- browser.find_element(s)_by_link_text(text)
- browser.find_element(s)_by_partial_link_text(text)
- browser.find_element(s)_by_name(name)
- browser.find_element(s)_by_tag_name(name)
の7種類でした。「element(s)」のところは、sを付けなければ一つ、sを付ければ、ページにあるその要素全てを取得する、という感じになります。
課題をやって思ったのですが、
ここまできたら「_by_xpath」を載せとけよ!(大声)
ということでした。(もしかしたらxpathを使わなくてもいけた……?)
今回はなんとなく、Yahoo mailのアカウントでコードを書いたのですが、id = “~~”って単純に使えるやつはあんまりなかったです。
むしろ、”data-test-id” とかいうクラス(?)になっていました。
そういう場合は
#celenium xpath example
title_elems = browser.find_element_by_xpath('//input[@data-test-id="compose-subject"]')という感じで書いてあげるとうまくいきます。英語でググったら割と早めにでてきました。
ということで、出来上がったコードはこちら(一部、個人情報的なところを変えてあります。)
#! python3
# check11_1.py - コマンドライン電子メーラー
# Usage
# python check11_1.py <sending mail address> <title> <text>
from selenium import webdriver
import sys
import time
print("Usage: python check11_1.py <sending mail address> <title of email> <text>")
#ドライバーの準備
browser = webdriver.Firefox(executable_path = r"C:\\Users\\~~\\geckodriver.exe") #geckodriver.exeまでのパス
USER_ID = "メールのユーザー名"
PASSWORD = "メールのパスワード"
#yahooへのログイン
browser.get("https://login.yahoo.com/?.src=ym")
email_elem = browser.find_element_by_id("login-username")
email_elem.send_keys(USER_ID)
email_elem.submit()
time.sleep(5)
password_elem = browser.find_element_by_id("login-passwd")
password_elem.send_keys(PASSWORD)
password_button = browser.find_element_by_id("login-signin")
password_button.click()
time.sleep(10)
#メール画面に移動
compose_elem = browser.find_element_by_xpath('//a[@data-test-id="compose-button"]')
compose_elem.click()
time.sleep(15)
#アドレス入力
address_elem = browser.find_element_by_id("message-to-field")
address_elem.send_keys(str(sys.argv[1]))
time.sleep(5)
#タイトル入力
title_elems = browser.find_element_by_xpath('//input[@data-test-id="compose-subject"]')
title_elems.send_keys(str(sys.argv[2]))
time.sleep(5)
#本文入力
text_elems = browser.find_element_by_xpath('//div[@data-test-id="rte"]')
text_elems.send_keys(" ".join(sys.argv[3:]))
time.sleep(15)
#送信
send_elems = browser.find_element_by_xpath('//button[@data-test-id="compose-send-button"]')
send_elems.click()コマンドラインに果敢にも改行をいれて本文を書いてみましたが失敗しました。
まあ今回はこんなもんで…
time.sleep(秒数)をやってあげないと、ブラウザの遷移前に要素を探し始めてしまって、エラーが出ます。
実際に送ったメールがこちら↓
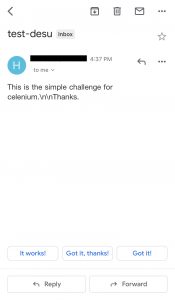
最終的に送信できた時はちょっとうれしかったですが、「xpath書いとけよ」が勝ってしまってプラマイゼロでした。
画像サイトのダウンローダー
クリア条件
写真共有サイトから
- 写真のカテゴリーを検索
- 検索結果の画像をすべてダウンロードする
モチベーションを上げるために、「cat fluffy」の画像を取得していきます。
#! python3
# check11_2.py - XKCDコミックをひとつずつダウンロードするのと近いやつ
import requests, os, bs4, sys, re
url = "https://www.flickr.com/"
os.makedirs("flickr", exist_ok=True)
#キーワードを文字列に
key_words = "+".join(sys.argv[1:])
#flickrにRequestを送る
res = requests.get("https://www.flickr.com/search/?text=" + key_words)
res.raise_for_status()
#soupの用意
soup = bs4.BeautifulSoup(res.text, features="html.parser")
links = soup.select(".photo-list-photo-view")
#example of url
#url(//live.staticflickr.com/6188/6113679188_6fd95914cf_m.jpg)
for i in range(len(links)):
img_url = re.search(r"url\((.+?)\)", links[i].get("style")).group(1)
print("https:" + img_url)
#ダウンロード
img = requests.get("https:" + img_url)
img.raise_for_status()
img_file = open(os.path.join("flickr", os.path.basename(img_url)), "wb")
for chunk in img.iter_content(100000):
img_file.write(chunk)
img_file.close()
print("Done")XKCDコミックをひたすら取得したコードを流用する感じにして書きました。
Flickrsで「Fluffy Cat」で調べていただけると癒されます。
2048
課題のクリア条件
数字の書かれたタイルをずらして遊ぶゲームを、コード書いて攻略します。
ゲーム自体はhttps://gabrielecirulli.github.io/2048にあります。
ゲームの流れとしては
- URLを開く
- New Gameを押す(押さなくてもいける)
- 上、右、左、下を繰り返す
- Gameoverが表示されたら終わり
CeleniumのKeys.UPなどを使ってなんとかなりそうな感じですね。
#! python3
# check11_3.py - 2048を攻略するコード
# url of 2048 is "https://gabrielecirulli.github.io/2048"
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import sys
import time
#ドライバーの準備
browser = webdriver.Firefox(executable_path = r"C:\\Users\\~~\\geckodriver.exe") #geckodriver.exeまでのパス
GAME_URL = "https://gabrielecirulli.github.io/2048"
NEW_GAME_BUTTON = "restart-button"
RETRY_BUTTON = "retry-button"
#2048 games
browser.get(GAME_URL)
time.sleep(10)
#elems
game_elem = browser.find_element_by_tag_name("html")
try:
while True:
game_elem.send_keys(Keys.UP)
time.sleep(0.05)
game_elem.send_keys(Keys.RIGHT)
time.sleep(0.05)
game_elem.send_keys(Keys.DOWN)
time.sleep(0.05)
game_elem.send_keys(Keys.LEFT)
time.sleep(0.05)
except KeyboardInterrupt:
print("Done")time.sleepを最初のうちは2秒とかにしていたのですが、0.05秒にしたらギュンギュン動いて麦茶ふきました。
感想
今回はおもった倍くらい時間を食ってしまいました。
ある程度のところで見切りをつけて、先にすすめる潔さが必要ですかね……
次の記事はこちら↓

“『退屈なことはPythonにやらせよう』その9(11章:Webスクレイピング)” に対して3件のコメントがあります。
コメントは受け付けていません。