『退屈なことはPythonにやらせよう』その11(13章:PDFとWord)
Python初心者です。『退屈なことはPythonにやらせよう』を走っています。
11回目の今回は、13章をやっていきます~。
Excelを扱うための、openpyxlをやった前回の記事はこちら↓
今回の目次
今回もサードパーティ製のモジュールを使っていきます。pythonでimportがうまくいかない場合は、Windowならコマンドラインでpip install、Macならsudo pip3 installをする必要があります。
公式ドキュメンテーションへのリンクは以下の通り
- PyPDF2: https://pythonhosted.org/PyPDF2/index.html
- Python-Docx:https://python-docx.readthedocs.io/en/latest/
それでは張り切っていきましょう!
1. PythonでPDFを扱うPyPDF2モジュール
PyPDF2の基本的な使い方
PyPDF2はサードパーティ製のモジュールです。使用前にWindowsならpip install PyPDF2、MacやLinuxならsudo pip3 install PyPDF2をコマンドラインやターミナルで実行する必要があります。
本章にて記載されているPyPDF2の基本の使い方は以下の通りになります。
- PDFからテキストを抽出
- PDFの暗号を解く
- PDFを作成する
- PDFを暗号化する
では順番に見ていきます。
PDFからテキストを抽出
PyPDFを使ったテキストの抽出には、「extractText()メソッド」を使用します。以下に使用例を載せておきます。
#! python3
#モジュールの読み込み
import PyPDF2
#ファイルの読み込み(バイナリ読み込みモード)
pdf_file = open("pdfファイルのパス", "rb")
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
#ページ指定
page_obj = pdf_reader.getPage(1) #最初のページは 0
#テキスト抽出
page_obj.extractText()文中のextractText()メソッドの公式ドキュメンテーションはこちら(リンク)です。
ちなみに、このままのコードだと日本語は文字化けしてしまいます。文字コードをいじってみたりもしたのですが、パッと解決には至りませんでした。とりあえずは、英語の文書だけで使っていきたいと思います。
PDFの暗号を解く
パスワードでロックされたPDFファイルをPython上で開くやり方です。開く許可が得られるだけなので、日本語がちゃんと読めるようになるわけではありません。
pdf_reader.isEncrypted #パスワードが必要なら、Trueが返る
pdf_reader.decrypt("パスワード") #パスワードの入力(残りの作業は上と同じ)PDFを作成する
新しいPDFファイルを作ることができます。ただ、Wordで文書を書いてPDFで保存するのと同じように、ここで言う「作る」には、文書を記入することは含まれていません。以下の操作を既存のPDFに加えて、それを新しいファイルとして保存する、という風にとらえて下さい。
PdfFileWriterで、できること
- ページをコピー
- ページを回転
- ページを重ね合わせる
- PDFを暗号化する
作業の流れは以下のようになります。
- PdfFileReaderオブジェクトを開く
- 保存先のPdfFileWriterオブジェクトを作る
- Readerオブジェクトのほうから、Writerオブジェクトのほうにコピーなどをする
- Writerオブジェクトを出力PDFファイルとして書き込む
Excelの時に、load_workbook(“既存のファイル”) → 作業 → Workbook()で作った新規シートに保存
みたいなことをやってたのと同じような流れですね。
ページをコピー
テキストごとを書き出す方法は書いていなかったので、ページをマルっとコピーする方法だけ紹介しておきます。
import PyPDF2
#準備
pdf_file = open("pdfファイルのパス", "rb") #pdfをバイナリ読み込みモードで読み込む
pdf_reader = PyPDF2.PdfFileReader(pdf_file) #PdfFileReaderオブジェクトにする
pdf_writer = PyPDF2.PdfFileWriter() #出力先のPDF
#pdfページのコピーと書き出し
page_obj = pdf_reader.getPage(page_number) #page_numberには取得したいページ番号をいれる
pdf_writer.addPage(page_obj)
#pdfページを新規ページとして出力
pdf_output_file = open("保存先 pdf ファイル", "wb")
pdf_writer.write(pdf_output_file)
#開いたファイル達を閉じる(これをやらないと、他のとこで開けなくなったりする)
pdf_output_file.close()
pdf_file_close()ページを回転
ページの回転は90°ごとにできます。
- rotateClockwise()
- rotateCounterClockwise()
の二つのメソッドが用意されており、引数として90、180、270を渡します。ページオブジェクトに対して行うので、以下のような流れになります。
import PyPDF2
#準備
pdf_file = open("pdfファイルのパス", "rb") #pdfをバイナリ読み込みモードで読み込む
pdf_reader = PyPDF2.PdfFileReader(pdf_file) #PdfFileReaderオブジェクトにする
#pdfページの回転
page_obj = pdf_reader.getPage(page_number) #page_numberには取得したいページ番号をいれる
page_obj.rotateClockwise(90)ページを重ね合わせる
mergePage()メソッドを使って、ページを重ね合わせることができます。「SECRET」みたいな赤いハンコが押された感じの書類がドラマで出てくるのをみたことありませんか?あんな感じのイメージのやつが作れます。(実際の機能はページを重ね合わせるだけなので、ハンコみたいなPDFを事前に準備する必要があります。)
import PyPDF2
#準備
pdf_file_main = open("pdfファイルのパス", "rb") #pdfをバイナリ読み込みモードで読み込む
pdf_file_ue = open("pdfファイルのパス", "rb") #pdfをバイナリ読み込みモードで読み込む
pdf_reader_main = PyPDF2.PdfFileReader(pdf_file_main) #PdfFileReaderオブジェクトにする
pdf_reader_ue = PyPDF2.PdfFileReader(pdf_file_ue) #PdfFileReaderオブジェクトにする
#pdfページの重ね合わせ
page_obj_main = pdf_reader_main.getPage(page_number) #page_numberには取得したいページ番号をいれる(重ね合わせの下)
page_obj_main.mergePage(pdf_reader_ue.getPage(page_number)) #重ね合わせたいページの番号(上になる側)PDFを暗号化する
write()メソッドで書き出す前に、encrypt(“パスワード”)とすると、暗号を設定することができます。
import PyPDF2
#準備
pdf_file = open("pdfファイルのパス", "rb") #pdfをバイナリ読み込みモードで読み込む
pdf_reader = PyPDF2.PdfFileReader(pdf_file) #PdfFileReaderオブジェクトにする
pdf_writer = PyPDF2.PdfFileWriter() #出力先のPDF
#pdfページのコピーと書き出し
page_obj = pdf_reader.getPage(page_number) #page_numberには取得したいページ番号をいれる
pdf_writer.addPage(page_obj)
#ここで暗号化
pdf_writer.encrypt("パスワード")
#pdfページを新規ページとして出力
pdf_output_file = open("保存先 pdf ファイル", "wb")
pdf_writer.write(pdf_output_file)
#開いたファイル達を閉じる(これをやらないと、他のとこで開けなくなったりする)
pdf_output_file.close()
pdf_file.close()encrypt()メソッドの引数には、
- ユーザーパスワード
- オーナーパスワード
を渡すことができます。ひとつしか渡さないと、どちらも同じものに設定されるようです。
2. PythonでWordファイルを扱う Python-Docx モジュール
Python-Docxモジュールでの読み込みから書き出しまで
Python-Docxモジュールを使うと、Word文書のファイルをPython上で扱うことができます。基本の流れとしては、以下の通りです。
- docxをインポート
- doc = docx.Document(“ワードファイル”)
- なんか色んな作業
(新しいファイルに書き出す場合) - doc_result = docx.Document()で白紙のファイルを生成
- doc_result.add_~~
- doc.save(“新しいワードファイル”)
という感じになります。(実際のコードは、演習プロジェクトのほうで)
公式ドキュメンテーションはこちら(リンク)になります。
Python-Docxで使うオブジェクトと属性
上のところで出てきた docx.Document(“ワードファイル”)では、「Documentオブジェクト」を生成しています。
Documentオブジェクトには、paragraphsという属性があり、そこにParagraphオブジェクトのリストが格納されています。Paragraphオブジェクトの中に、text属性があり、このtext属性に文字が格納されています。ここのtext属性に格納されているのは、Paragraphの中にある文字です。これとは別に、ParagraphオブジェクトはRunオブジェクトの集合体でもあります。Runオブジェクトは文字のスタイル(フォントの種類や大きさなど)が変わるたびに新たなRunオブジェクトとなります。そして同じスタイルのまとまりであるRunオブジェクトもText属性を持っています。スタイルの違いで区切られる箱の中に入っている文字列です。
ちょっと入り組んできたので、図を用意しました。
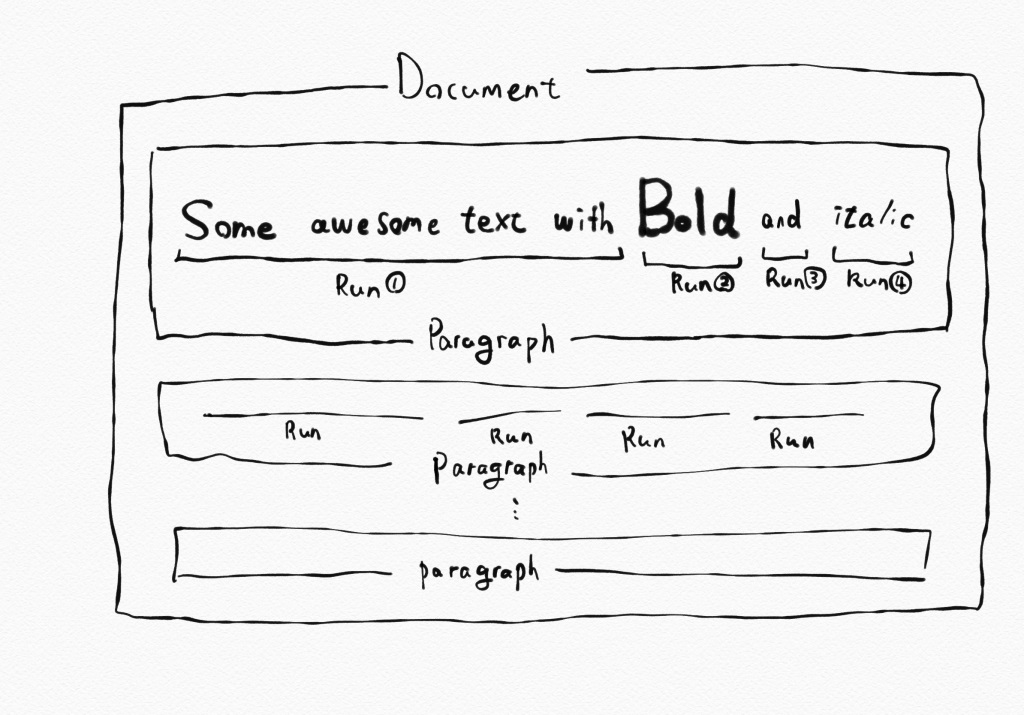
paragraphの中のtext属性を取得すると「Some awesome text with Bold and italic」が取得できます
Run①のtext属性を取得すると、「Some awesome text with」が取得できます。
DocumentオブジェクトはいくつかのParagraphからできていて、ParagraphオブジェクトはいくつかのRunオブジェクトからできています。
勝手なイメージですが、ParagraphはHTMLで言うところの<p>タグで、runは<span>とかに近いのかなと思います。(spanは全部につくわけではありませんが)
Paragraphを追加する際に、変数に格納しておくと、runオブジェクトを足して文字を増やしていくときも楽になります。
import docx
#白紙のワードファイル作成
doc = docx.Document()
#段落の追加
para_obj1 = doc.add_paragraph("一段落目のテキストを書き始める。")
para_obj2 = doc.add_paragraph("二段落目のテキストを書き始める。")
#段落にテキストを足したい。
para_obj1.add_run("1段落目に追加したいテキストを書く。")
#ページ区切りを入れたい
#ここまで前のページ
doc.add_page_break()
#ここから次のページ
#見出しの追加
doc.add_heading("見出しの文字", 0~4)) #見出しは0が大きくて、4が小さい感じになります。
#ワードファイルを保存する
doc.save("保存したいワードファイルの名前")Paragraphから文字列を取得するには、「paragraphオブジェクト.text」とすれば大丈夫です。
3. 13章 演習プロジェクト
課題1:PDFをまとめて暗号化
9章で扱った(記事はこちら)、os.walk()の関数を応用して、フォルダ内のファイルをすべてチェックし、pdfがあればそれを暗号化するプログラムを書きます。実際に書いたコードがこちら。
#! python3
# check13_1.py - フォルダの中のpdfを全て見つけて暗号化する
#debug
import logging
logging.basicConfig(level=logging.DEBUG,
format = " %(asctime)s - %(levelname)s - %(message)s")
logging.debug("プログラム開始")
#logging.disable(logging.CRITICAL)
#walk
import os, PyPDF2
for foldername, subfolders, filenames in os.walk(os.getcwd()):
logging.debug("The current folder is " + foldername)
for subfolder in subfolders:
logging.debug("SUBFOLDER OF " + foldername + ": " +subfolder)
for filename in filenames:
if filename.endswith(".pdf"):
logging.debug("FILE INSIDE " + foldername + ": " + filename)
logging.debug("{}の暗号化を開始します".format(filename))
pdf_file = open(filename, "rb") #pdfを開く
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
if not pdf_reader.isEncrypted:
pdf_writer = PyPDF2.PdfFileWriter() #新規のpdfを作成
for page_num in range(pdf_reader.numPages):
pdf_writer.addPage(pdf_reader.getPage(page_num))
pdf_writer.encrypt("bananafish") #暗号化
result_pdf = open(filename[:-4] + "_encrypt.pdf", "wb")
pdf_writer.write(result_pdf)
result_pdf.close()
else:
print("{}は既に暗号化されています".format(filename))
logging.debug("{}の暗号化が完了しました".format(filename))
print("")
logging.debug("プログラム終了")
骨組みはos.walk()のままです。filenameが「.pdf」で終わる場合のみprint()で表示するところから始めました。あとはPyPDF2でpdfファイルを暗号化する手法をそのまま使っています。
工夫した点としては、既に暗号化されているpdfファイルにぶつかった場合は、暗号化処理をスキップして次のループに移るようにした点ですね。
課題2:Word文書による特製招待状
テキストファイルで渡された名前のリストから名前を取得して、ワードファイルで招待状を書くプログラムです。一応ひな形が用意されており、デフォルトの状態から少しスタイルをいじるのも課題の一つでした。
- 中央ぞろえ
- フォント変更(種類とサイズ)
- 下線を引く
などのスタイル変更を行いました。
#! python3
# check13_2.py - テキストファイルから名前を受け取り、それに合った招待状を作成する。
#debug
import logging
logging.basicConfig(level=logging.DEBUG,
format = " %(asctime)s - %(levelname)s - %(message)s")
logging.debug("プログラム開始")
#logging.disable(logging.CRITICAL)
import docx
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt
to_send_file = open("guests.txt", "r")
guests = to_send_file.readlines()
to_send_file.close()
doc = docx.Document()
for guest in guests:
#text
#para1
para_obj1 = doc.add_paragraph("It would be a pleasure to have the company of")
#para2
para_obj2 = doc.add_paragraph(guest.rstrip("\n"))
para_obj2.runs[0].underline = True
#para3
para_obj3 = doc.add_paragraph("")
para_obj3.add_run("at")
para_obj3.add_run(" 11010 Memory of Lane on the Evening of")
para_obj3.runs[0].underline = True
#para4
para_obj4 = doc.add_paragraph("April 1st")
#para5
para_obj5 = doc.add_paragraph("")
para_obj5.add_run("at")
para_obj5.add_run(" 7 o'clock")
para_obj5.runs[0].underline = True
doc.add_page_break()
#alignment
for para in doc.paragraphs:
para.alignment = WD_ALIGN_PARAGRAPH.CENTER
#font-size
for run in para.runs:
font = run.font
font.name = 'Calibri'
font.size = Pt(20)
doc.save("invitations.docx")
logging.debug("プログラム終了")見やすさを重視したら縦に長いコードになってしまいました。テキストファイル上では、一行につき一人の名前が記載されているため、文字列にすると
「人の名前\n」
となり、改行が入ってしまいます。この変な改行を除くためにstr.stripメソッドを適用しました。また、ページ区切りを招待状の最後に入れることで、そのまま印刷して送れるような形になっています。
参考にしたサイトも一応書いておきます。
中央ぞろえ:https://python-docx.readthedocs.io/en/latest/api/enum/WdAlignParagraph.html
フォント変更:https://python-docx.readthedocs.io/en/latest/user/text.html
課題3:総当たり方式のPDFパスワード解除
pdfの暗号を忘れてしまった場合に、単語をとにかく入れまくって解除しようというプログラムです。dictionary.txtという辞書ファイルは本書の日本語版のGithubに載っているのですが、ここには載せないでおきます。それ用に自分が書いたコードだけ載せておく感じにしようと思います。
#! python3
# check13_3.py - 総当たり法でpdfをアンロックする
#debug
import logging
logging.basicConfig(level=logging.DEBUG,
format = " %(asctime)s - %(levelname)s - %(message)s")
logging.debug("プログラム開始")
logging.disable(logging.CRITICAL)
import PyPDF2
en_file = "allminutes_encrypt.pdf"
dic_file = open("dictionary.txt", "r")
key_dict = []
for keys in dic_file.readlines():
key_dict.append(keys)
logging.debug("ket_dictの長さは{}".format(len(key_dict)))
dic_file.close()
logging.debug(key_dict[:5])
logging.debug("pdfを準備しています。")
pdf_file = open(en_file, "rb")
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
#pdfの暗号を解読
print("pdfの暗号を解読します。")
for count, key in enumerate(key_dict):
trial1 = pdf_reader.decrypt(key.strip("\n").lower())
trial2 = pdf_reader.decrypt(key.strip("\n").upper())
if trial1 == 1:
print("キーワードは{}でした。".format(key.strip("\n").lower()))
break
elif trial2 == 1:
print("キーワードは{}でした".format(key.strip("\n").upper()))
break
else:
logging.debug("{}番目の{}はキーワードではありませんでした".format(count, key))今回も、キーワードのリスト自体には語尾に改行が入っているので「文字列.strip(“\n”)」としています。テキストファイルには大文字が格納されているので、upper()とlower()のどちらも試す感じにしました。大文字になる場所が変わってしまうと対応できないのですが、おそらく文字列のメソッドを追加すれば大丈夫だと思われます。
4. 感想
最近更新ペースが落ちてきています。すみません…
触ってみた感じ、PyPDF2は今のところあんまり使わないかなという気がします。うまく日本語が抽出できない(文字化けする)ので、選択をしてWordに貼り付けてPython-docxでテキストを取得したほうが確実な気がしますよね。Paragraphオブジェクトに対して.textメソッドで取り出せば、日本語でも大丈夫ですし。最悪、Wordに貼り付けなくても、pyperclipモジュールでも良いですし。一応Adobeの有料のやつを使うと、pdfからWordに変換するのもそんなに大変じゃないみたいです。でもテキストとして認識されない、スキャンしてPDFにしたやつみたいなのを、OCRとかを使ってPDFにした後、テキストとして読みたいみたいなこともあると思うので、行く行くは文字コードの壁を越えられるようにしたいと思います。
python-docxで文章を書くのもけっこう面倒です。add_run()メソッドを使って、それぞれにスタイルを変更するのも結構めんどいです。順番とかをいちいち覚えてないといけないですからね。現実的な使い方としては、add_paragraph()で、段落ごとの文字列をPythonで渡して、こまかい調整(下線とか太字とか)はWordでやったほうが普通の文書には速いと思いました。ただ、招待状みたいにある程度フォーマットが決まっていて、短いけれど似たものを何枚も作る、みたいな時にはPython上で文書を作ったほうが便利ですね。
2020/7/18 追記 (日本語PDFはpdfminer.sixモジュールで文字化けせずいける)
pipを使ってインストールする時は「pip install pdfminer.six」という名前になります。
公式ドキュメンテーションへのリンクはこちら。最近やってた『できる 仕事が捗るPython自動処理 全部入り。』でさらっと出てきました。写経はそこまで身にならない説もありますが、初心者としてあがく段階ではやはりためになりますね。大事なのは時間をかけすぎず、さらっといくことですね。
次の記事はこちら↓

pdfの暗号化のプログラムを参考にさせて貰いました。ありがとうございます!
ただ、pdf_file.close()をpdf_file_close()と書き間違えておられたので、他の方が参考にするときの為にも直していただけると幸いです。
とても助かりました。
吉田翼さん
ご指摘ありがとうございます!
修正いたしました。